
Betting is often influenced by luck. Sometimes we can benefit from good luck, and other times we can be the victims of bad luck. It’s important to understand the part luck can play in betting, but just how fine is the line between good and bad luck? Read on to find out.

Sports betting is pretty much all about chance. Those who win do so almost entirely because of good luck; the bookmaker’s margin and the law of large numbers will defeat nearly of them in the end. Those of you familiar with my articles over the years will know that I tell a pretty uncompromising story when it comes to the likelihood of bettors actually making a profit over the long run. I don’t necessarily expect you to agree with it, since it marks the battleground any bettor faces between hope and realism.
To counter this narrative, many of Pinnacle’s Betting Resources articles are designed to educate bettors to become more skilled at prediction. Nevertheless, even for those few who do manage to find a profitable long term expectation, the rules of probability will still apply. In this article I’ll take a closer look at how. In particular I will illustrate just how fine the line is between good and bad luck.
The classic coin toss example
We all know that tossing a coin is a 50-50 proposition: heads or tails. We also know that if we toss it 20 times, we won’t always get 10 heads and 10 tails, although that is the most likely outcome. Sometimes we’ll get 12 heads and 8 tails, sometimes the other way around. Very occasionally we might see 5 heads and 15 tails. To determine the exactly probabilities of each possible outcome we can use the binomial distribution. For 20 coin tosses it will look like this.
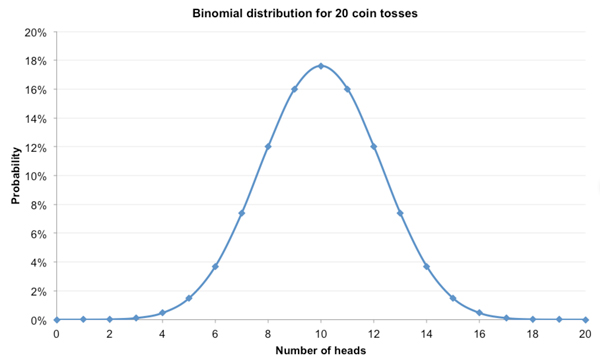 Most of the likely outcomes range from between 5 heads and 15 tails to 15 heads and 5 tails. What about for 100 coin tosses? The distribution will look like this.
Most of the likely outcomes range from between 5 heads and 15 tails to 15 heads and 5 tails. What about for 100 coin tosses? The distribution will look like this.
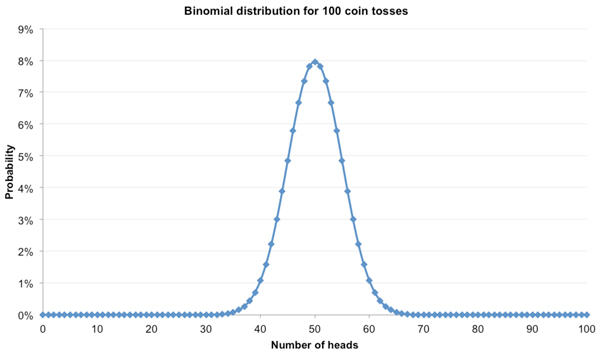 This time the range of likely outcomes is bigger. Visually, for 20 coin tosses it is between 5 and 15 heads, a difference of 10. For 100 coin tosses, that range is roughly double, between 40 and 60 heads. Does that mean that as the sample size of coin tosses grows larger, the range of possible outcomes grows too? Well, yes and no.
This time the range of likely outcomes is bigger. Visually, for 20 coin tosses it is between 5 and 15 heads, a difference of 10. For 100 coin tosses, that range is roughly double, between 40 and 60 heads. Does that mean that as the sample size of coin tosses grows larger, the range of possible outcomes grows too? Well, yes and no.
When the mathematician Jacob Bernoulli experimented with such a scenario, he observed that whilst the absolute numerical difference between the number of heads and tails might get bigger with increasing sample size, the percentage of heads gets closer to 50%. 5 out of 20 heads is equal to 25%; 40 out of 100, however, is equal to 40% This second explanation, which forms the basis of the law of large numbers, is the important part for bettors’ understanding of probability.
The binomial standard deviation
We can measure the range or dispersion shown in a distribution by means of the standard deviation. For a binomial distribution, the standard deviation, σ, is given by the following simple equation.
![]()
Where n is the number of binary repetitions (e.g. coin tosses), p is the probability of success (heads) and q is the probability of failure (tails). Since p + q = 1:
![]()
And for the simple case where p = q (i.e. 0.5):
![]()
For 20 coin tosses, σ = 2.24, whilst for 100 coin tosses, σ = 5.
The standard deviation tells us the range of most of the possible outcomes. For example, for 100 coin tosses, a little over two-thirds of samples will lie between ±1σ, or between 45 and 55 heads.
We’ve confirmed Bernoulli’s first finding: the greater the sample size, the greater the absolute spread. However, what if we use percentages of heads instead of absolute numbers? To calculate the percentage of heads we divide their number by the total number of coin tosses, n. Similarly, to calculate the standard deviation in percentages, we must also divide by n.
Hence for simple 50:50 propositions:
Now, for 20 coin tosses the standard deviation in the percentage of heads is 0.11 (or 11%), but for 100 coin tosses it’s just 0.05 (or 5%).
The law of large numbers
According to the law of large numbers, the average of the results obtained from a number of trials should tend closer towards the expected value as more trials are performed. For coin tossing, the more times we toss the coin, the closer the percentage of heads will be to the expected value of 50%.
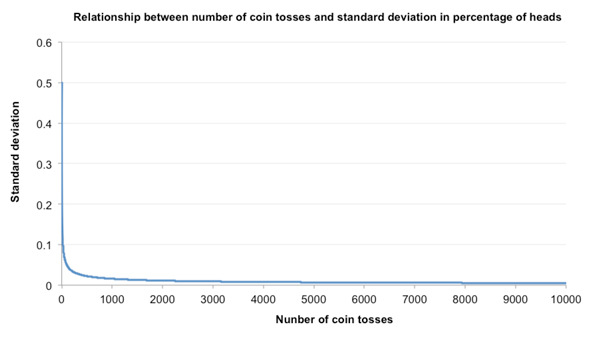
Since the standard deviation in percentages is proportional to the square root of the number of coin tosses, the two variables form what is known as a power law relationship, with standard deviation varying with the power or logarithm of the number of tosses. On a log-log plot, the relationship reveals itself as a straight line; with each squaring of n, the value of σ halves.
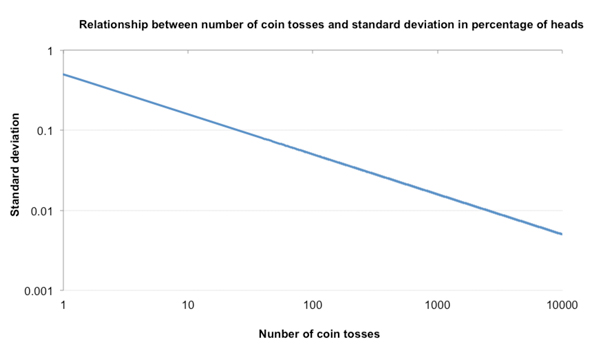
This power law relationship means that, proportionally speaking, most of the fall in standard deviation occurs in the first few trials. From σ=0.5 after 1 coin toss, it has fallen to just 0.1 after only 25 tosses, four-fifths of the way towards the limit value zero (after an infinite number of tosses). In this way we can appreciate how quickly the law of large numbers actually gets to work. Redrawing the chart above with linear scales should help visualise this speed.
Wins and losses in betting
Win and losses in betting are very much like heads and tails in coin tossing. A bet is essentially a binary proposition: it either wins or it doesn’t. As such, for the simplest betting histories where the expected probability of each win remains the same, the possible outcomes will also be binomially distributed.
An obvious example of this binary proposition would be point spread betting US sports markets, or Asian Handicap football where the application of a handicap to one side or the other turns the bet into a 50-50 proposition, with fair odds of 2.00.
However, we needn’t restrict ourselves to just 50-50 propositions. Recall the equation above for the standard deviation in percentages. The more generic version which allows you to consider other possible expected win percentages is as follows.
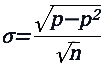
Even for skilled bettors capable of generating long term profitable expected value, most of what happens will be random noise around a relatively weak signal, simply because of the inherent random variability of complex systems like sporting events.
Of course in the real world of betting, unskilled bettors don’t break even by meeting expectation. Once you factor in the bookmaker’s margin it’s essentially inevitable that you will lose money after 1,000 wagers.
Imagine a bettor betting 50-50 propositions and winning 55% of them over the long term. They have shifted their expected win percentage from 50% to 55% through their predictive skill, but the same binomial rules of variance will still apply.
With the equation above we could show that their standard deviation in bet win percentage should be 3% after 275 bets, implying roughly a two-thirds probability that their win rate will be between 52% and 58% for that size of betting history.
Provided our betting remains simple with the same expected win probability (odds) for every wager, we can use the binomial distribution to pretty much determine the probability of anything happening (in Excel this can be performed with the function BINOMDIST).
I’ve illustrated this for a series of betting histories below. The first is a history of just 20 wagers. The numerical values in the plot show the cumulative probability of the actual win percentage being higher than a particular value. For example, you have about a 9% chance of winning more than six bets (30%) if your long term expectation is 20%. You have roughly a 1% chance of winning 20 out of 20 if typically you’d expect to win 16.
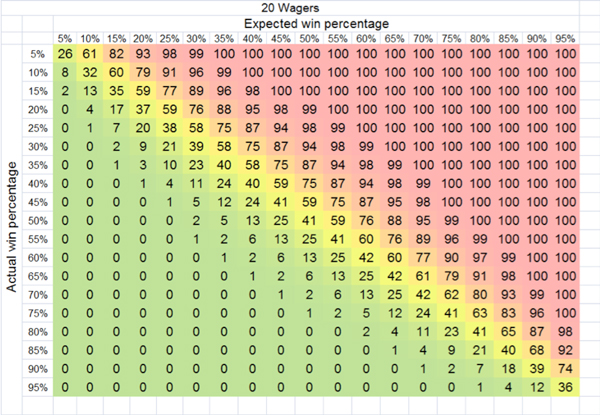
The red and green zones, broadly speaking, mark the zones of loss making and profit taking respectively, where the odds are fair. Unsurprisingly, if you lose more bets than you’re expected to, you will make a financial loss, but you can see that significant under performance isn’t very common.
Even after just 20 even-money wagers three-quarters of the time you can expect to win nine or more. The law of large numbers is on your side, protecting you against the likelihood of significant percentage losses.
However, the corollary is also true. If you win more bets than you’re expected to, you will make a profit, but it’s not that likely you’ll make big profits. Even if you’re a skilled bettor capable of winning 55% of even-money wagers over the long run, you still only have a 13% chance of winning 14 or more out of 20. Now the law of large numbers is against you, preventing you from making significant percentage gains.
The yellow region is roughly the region where bettors will be breaking even. What is striking is just how fine the zone between excessive good and bad luck is, and where most betting performances will be found.
Look what happens to the yellow zone after 100 wagers.
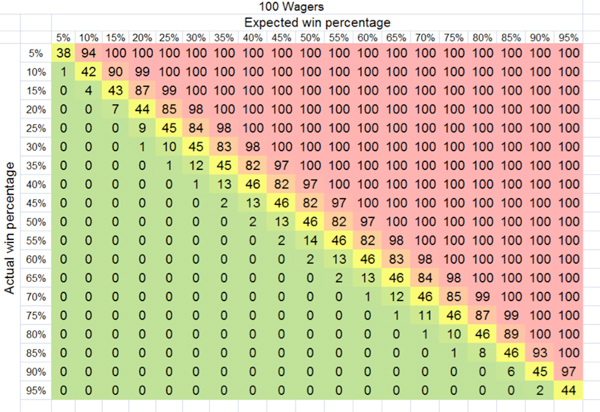
The chances of finding yourself very far removed from long term expectation have shrunk considerably. And after 1,000 wagers?
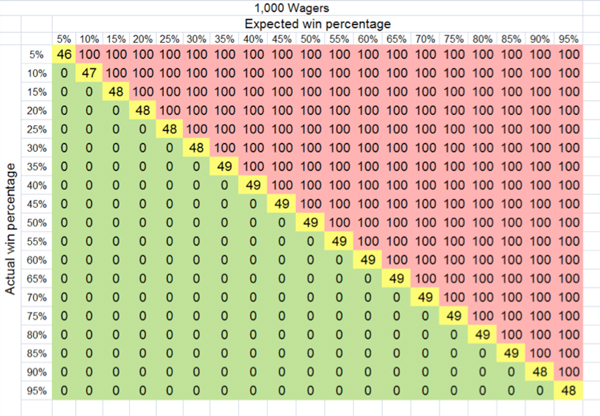
Of course in the real world of betting, unskilled bettors don’t break even by meeting expectation. Once you factor in the bookmaker’s margin it’s essentially inevitable that you will lose money after 1,000 wagers. The law of large numbers has destroyed you. For skilled bettors, however, the picture is very different.
If you expect to win 55% of 1,000 even-money propositions, almost always you will win at least 50% of them. Provided the bookmaker’s margin is smaller than the difference between what you expect your winning percentage to be, and what the bookmaker thinks that winning percentage should be, you have a very good chance of making a long term profit. The respected website ProfessionalGambler.com very much makes this point:
“the difference between the percentage of bets won by successful sports bettors and the percentage of bets won by chronic losers is relatively very small.”
Now you can see just how small it is. The law of large numbers truly has the ability to be both a bettor’s blessing and curse.
Obviously most people’s betting is not as simple as this article suggests, with bettors choosing a variety of odds and stakes. To analyse these, we would need to use far more sophisticated mathematics or turn to our friend the Monte Carlo simulation where that becomes too complex.
Additionally, I haven’t considered the variances in actual profits and losses which is another topic of interest altogether and one which I’ve touched on in previous articles (the longer the odds, the greater the variance in profits and losses).
Nevertheless, the purpose of this article was to illustrate the speed and power of the law of large numbers and just how fine the line is between expected and actual outcomes, and the realms of good and bad luck.
Testing the credibility of betting histories
Before closing, I also want to show you how you can use information about the standard deviation in actual win percentages to test the credibility of betting histories claimed by tipping advisory services hoping to sell you their picks.
We can use an example of a handicapping firm that provides an “honest and upfront approach” to their “handicapping principles.” The firm is evidently aware of randomness in sports betting, explaining to customers that there is no such thing as a guaranteed winner, and that “there is always an element of luck in every contest.” Nevertheless, with a published win rate of 76% from over 11,000 picks, they have evidently managed to subdue its fickleness.
According to the law of large numbers, the average of the results obtained from a number of trials should tend closer towards the expected value as more trials are performed.
Examining more closely their published results to date in fact reveals a win rate of 75% from 10,312 picks (evidently a few tips are missing). Although there are a few short and long priced propositions, 94% of them have odds between 1.67 and 2.50 (or 60% and 40% implied win probabilities). The average implied win probability for the whole sample is 52.2% which after the bookmaker’s margin is removed, is as close to a 50-50 proposition as makes no difference.
Breaking the results into 56 monthly samples (from March 2014 to October 2018) reveals an average monthly pick total of 184, with over half of them between 140 and 224 picks. If we assume that the long term expected win rate is 75%, how much should their monthly win percentages vary by? Using our equation above for calculating the expected standard deviation in win percentages for sample of 184 picks, we find the answer to be a little over 3%. Just over two-thirds of samples should be between about 72% and 78%, whilst 95% would be between about 69% and 81%.
In fact, the standard deviation in monthly win percentages is 8.6%, far higher than it should be. Fewer than 40% of values lie within ±1σ of 75% and just over half within ±2σ. There is simply too much variation. Even if we assumed that every month had 32 picks only, the month with the fewest number, the expected standard deviation would still only be 7.7%.
A standard deviation in monthly win percentages of 8.6% would typically be expected for picks samples of around 25, not 184. December 2014 saw 151 picks at an average implied win expectation of 51.4%. The win percentage of 46.4% would be expected once in a million billion years. October 2015 had 168 picks (average implied win expectation 48.5%) winning 154 or 91.7% of them. Such a performance for such a skilled tipster would normally only happen roughly once every million years.
I will leave it to your imagination to determine what these findings might suggest. Perhaps it’s an argument that skill levels can fluctuate dramatically over short periods of time. Perhaps it’s an argument for something else. Given what I’ve had to say previously about the limits of profit expectation, however, I’m sure you already knew that a handicap win rate of 76% is something to chuckle about and move on.
MORE: TOP 100 Online Bookmakers >>>
MORE: TOP 20 Bookmakers that accept U.S. players >>>
MORE: TOP 20 Bookmakers that accept Cryptocurrency >>>
Source: pinnacle.com